The CAP theorem is a fundamental principle in distributed computing that states that it is impossible for a distributed system to simultaneously provide all of the following three guarantees and must choose between the two of them, at the expense of the third:
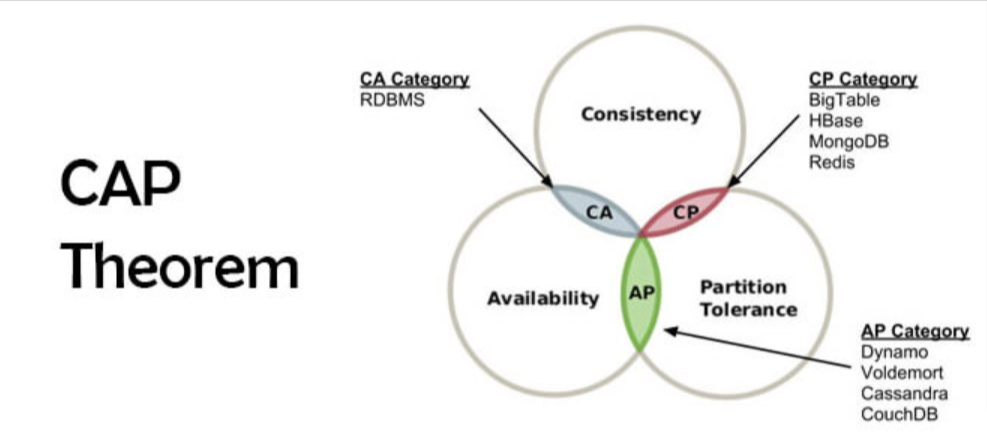
- Consistency: Every read operation from the system returns the most recent write or an error. In a consistent system, all nodes see the same data simultaneously. However, there are several strategies and techniques that can be used to achieve consistency:
- Replication: Replication involves creating multiple copies of data and distributing them across multiple nodes in the system. However, it’s important to ensure that updates are applied to all copies of the data before returning a response to the client, to prevent inconsistencies from arising.
- Consensus protocols: Consensus protocols are algorithms that typically involve a group of nodes agreeing on a value through a series of rounds of communication and voting eg Raft and Paxos.
- Distributed transactions: Distributed transactions are transactions that span multiple nodes in a distributed system. These transactions typically involve a two-phase(2P) commit protocol. Two-phase commit is a distributed transaction protocol that involves a coordinator node and multiple participant nodes. The coordinator node coordinates the commit or abort of the transaction, and the participant nodes agree to either commit or abort the transaction based on the coordinator’s decision. 2PC can help ensure consistency by ensuring that all nodes involved in the transaction commit or abort together.
- Distributed Locking: In some cases, conflicts can arise when updates to data are made concurrently on different nodes. Conflict resolution techniques include optimistic locking, where nodes check for conflicts before committing updates ( and if there are conflicts, resolve them using versions/ timestamps before committing the changes), and pessimistic locking, where nodes lock data before updating it to prevent conflicts.
- Multi-version concurrency control (MVCC): Version control techniques (using version numbers or timestamps) can be used to track changes to data and ensure that updates are applied in the correct order. This can help to prevent conflicts and ensure that data is consistent across nodes.
- Availability: Every non-failing node in the system returns a response to read or write requests in a reasonable amount of time. That the system remains operational all of the time. Here are some key strategies for achieving high availability in distributed systems:
- Redundancy: One common approach to achieving high availability is to use redundancy. This involves having multiple copies of data or services distributed across multiple nodes in the system. If one node fails or goes offline, other nodes can take over and ensure that the system remains available. Redundancy can be implemented using techniques such as replication, load balancing, and failover mechanisms.
- Load balancing: Load balancing is a technique that involves distributing traffic across multiple nodes in the system. This can help to ensure that no single node becomes overloaded or becomes a single point of failure. Load balancing can be implemented using technologies such as round-robin DNS, hardware load balancers, or software load balancers.
- Failover mechanisms: Failover mechanisms are used to ensure that if a node fails, another node can take over its responsibilities. This can be achieved using technologies such as clustering, hot standby nodes, or active-passive configurations.
- Monitoring and alerting: To ensure high availability, it’s important to monitor the health of the system and detect failures as quickly as possible. This can be achieved using tools such as monitoring software, log analysis tools, and alerting mechanisms that notify administrators or operators of potential issues.
- Fault tolerance: Fault tolerance is a key aspect of high availability. This involves designing the system to be resilient to failures and to continue operating even if individual components fail. Techniques for achieving fault tolerance include using redundant components, implementing error handling and retry mechanisms, and ensuring that the system can recover from failures.
- Partition tolerance: The system continues to function correctly even when there are network partitions, which can cause nodes in the system to become temporarily disconnected from one another. Here are a few approaches that can be used to achieve partition tolerance in distributed systems:
- Replication: One common approach to achieving partition tolerance is to replicate data across multiple nodes in the system. This way, even if some nodes become temporarily disconnected from the rest of the network, other nodes will still be able to provide access to the replicated data.
- Quorum-based protocols: In a quorum-based protocol, a subset of nodes in the system (known as a quorum) must agree on a decision before it can be considered valid. This approach ensures that the system can continue to operate even if some nodes are temporarily disconnected.
- Cassandra database uses a quorum-based protocol for both read and write operations
- Hadoop Distributed File System (HDFS) uses a quorum-based protocol to ensure partition tolerance and high availability.
- ZooKeeper coordination service uses a quorum-based protocol to ensure that locks and other synchronization primitives are maintained consistently across multiple nodes.
- Consensus algorithms: Consensus algorithms, such as Paxos and Raft, can be used to ensure that nodes in a distributed system can reach agreement on a shared state, even in the presence of failures or network partitions. These algorithms typically involve a leader node that is responsible for collecting and coordinating updates to the shared state from at least one node from each partition (until it has received requests from a quorum of nodes). If the leader node fails, a new leader is elected.
- Google Spanner database uses a consensus algorithm known as Paxos to ensure that nodes in the system agree on a consistent version of the database.
- In a blockchain, consensus algorithms are used to ensure that all nodes in the network agree on the current state of the ledger. The consensus algorithm used in the Bitcoin blockchain is called Proof of Work (PoW), while other blockchains such as Ethereum use other consensus algorithms such as Proof of Stake (PoS).
- Anti-entropy protocols: Anti-entropy protocols can be used to ensure that data remains consistent across multiple nodes in a distributed system. These protocols involve periodically exchanging data between nodes to ensure that any differences are reconciled.
- One example is distributed version control systems, such as Git. In Git, each developer has a local copy of a repository that they work on, and periodically pushes their changes to a central repository. The central repository uses an anti-entropy protocol to ensure that all copies of the repository are consistent, even if some developers have made conflicting changes.
- In distributed databases such as Riak, data is stored across multiple nodes, and anti-entropy protocols are used to ensure that all nodes have consistent copies of the data.
Here are some examples of technical tradeoffs in distributed systems design with sample scenarios:
- Consistency vs. Availability:
The tradeoff between consistency and availability is particularly relevant in social media platforms where there is a large amount of user-generated content. Ensuring consistency can be challenging, as updates and changes to the content must be propagated to all users in a timely manner. This can result in delays and potential data conflicts, which can impact availability and hence, the user experience. On the other hand, prioritizing availability may result in inconsistencies between different users’ views of the content.
- Latency vs. Consistency:
Consider a scenario of a financial application where a customer initiates a transaction at an ATM machine to withdraw money from their account. If the bank prioritizes low latency over consistency, the transaction may be processed quickly but may not immediately update the customer’s account balance or send a notification to their mobile device. This could result in the customer believing that they have more money in their account than they actually do, leading to overdrawn accounts, fees, and potentially negative customer experiences.
Alternatively, if the bank prioritizes consistency over latency, the transaction may be held for a longer period to ensure that all copies of the data are updated in a timely and uniform manner. This can result in a delay in the time it takes for the customer to receive their money, which could potentially frustrate the customer and lead to negative experiences.
- Performance vs. Fault Tolerance:
Consider a distributed file storage system used by a cloud computing provider. If the system prioritizes performance, it will minimize network overhead and reduce redundancy, resulting in faster data transfers, but this can also make the system more susceptible to node failures and data loss. Alternatively, if the system prioritizes fault tolerance, it will replicate data and increase redundancy, resulting in higher availability and less data loss, but this can also result in increased network overhead and reduced performance.
- Centralized vs. Decentralized Control:
Consider a messaging platform that allows users to send messages to each other. If the system has a centralized control model, all messages will be routed through a single node, making it easier to manage message delivery and ensure consistency, but this also creates a single point of failure. Alternatively, if the system has a decentralized control model, messages can be routed through multiple nodes, making the system more fault-tolerant and less susceptible to a single point of failure, but this also adds complexity and increases the potential for inconsistencies in message delivery.
In summary, technical tradeoffs in distributed systems design involve balancing competing priorities such as consistency, availability, latency, fault tolerance, and efficiency. The specific tradeoffs chosen will depend on the requirements of the system and the needs of its users.