Distributed systems are computer systems made up of multiple interconnected and independent nodes that work together to achieve a common goal. The nodes can be geographically dispersed and are heterogenous in nature, making it possible to build large-scale systems that are highly available, fault-tolerant, scalable, and flexible.
By distributing the workload across multiple nodes, the system can continue to operate even if one or more nodes fail. Additionally, a distributed system can scale up or down depending on the demand for resources, making it possible to handle large workloads efficiently.
Examples of distributed systems include content delivery networks, social media platforms, distributed databases, and distributed file systems.
Some of the main components of a distributed system:
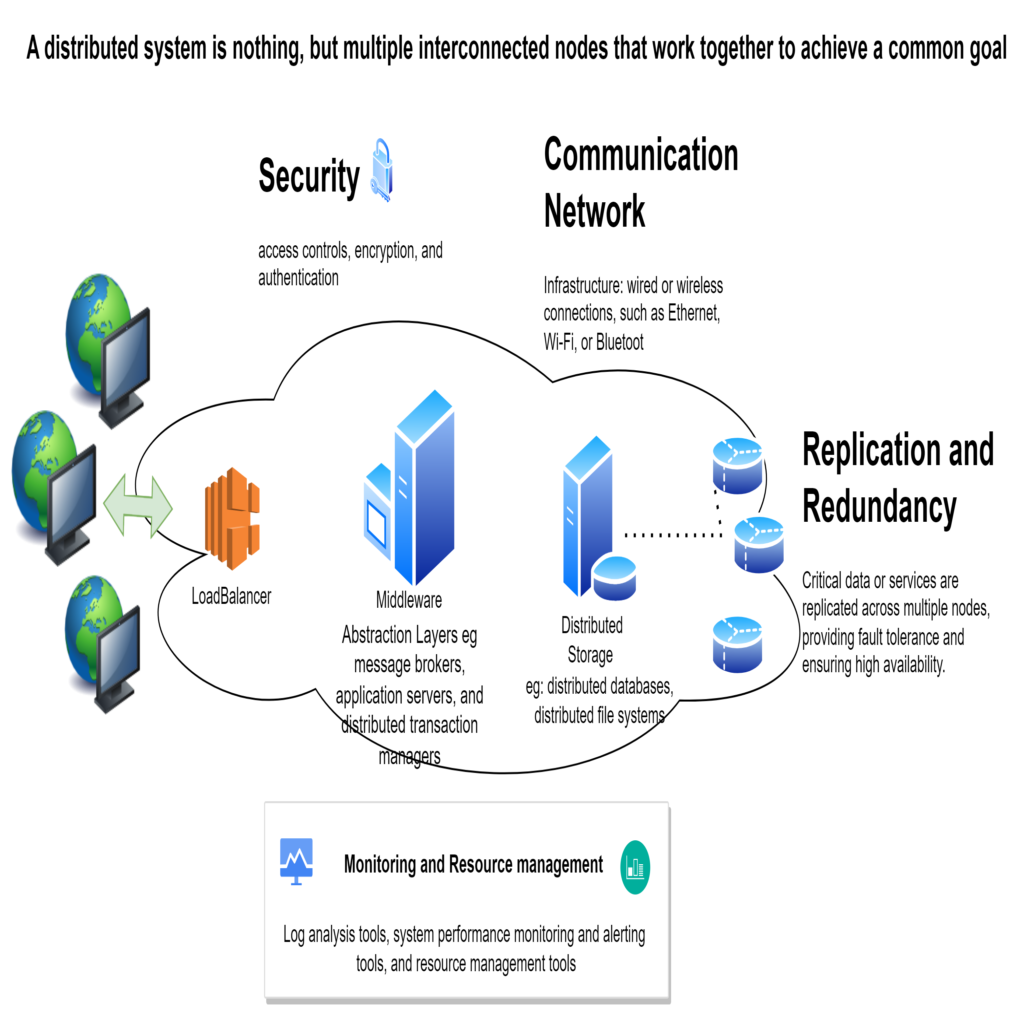
Key properties of distributed systems:
- Concurrency: In a distributed system, multiple nodes operate concurrently, executing tasks in parallel. This concurrency enables the system to handle multiple requests simultaneously, making it possible to achieve high performance and scalability.
- Multi-threading: Multi-threading involves creating multiple threads within a single process. Each thread can run independently and handle a different task, allowing multiple tasks to be executed simultaneously. However, care must be taken to avoid race conditions and deadlocks.
- Asynchronous programming: Asynchronous programming involves using non-blocking I/O operations to allow a single thread to handle multiple tasks concurrently. This can be achieved using event-driven programming or callback functions.
- Parallel processing: Parallel processing involves dividing a large task into smaller subtasks and executing them simultaneously on multiple processors or cores. This can help to improve performance by reducing the time required to complete the task.
- Distributed computing: Distributed computing involves dividing a task across multiple servers or resources and executing them simultaneously. This can help to improve scalability and performance by distributing the workload across multiple resources.
- Message passing: Message passing involves communicating between threads or processes using messages. This can help to avoid race conditions and deadlocks by synchronizing access to shared resources.
- Locking and synchronization: Locking and synchronization involves using locks or semaphores to prevent multiple threads from accessing a shared resource simultaneously. This can help to avoid race conditions and ensure data consistency.
- Non-blocking algorithms: Non-blocking algorithms are designed to avoid blocking threads or processes by allowing multiple operations to proceed simultaneously. This can help to improve performance and scalability by reducing contention for shared resources.
- Heterogeneity: Distributed systems are typically composed of nodes that have different hardware, software, and network configurations. This heterogeneity makes it possible to build systems that are flexible and adaptable to different use cases and environments.
- Communication: Communication between nodes in a distributed system is essential for exchanging data and coordinating actions. Communication can be synchronous or asynchronous, and there are various communication protocols and mechanisms available, including message passing, remote procedure calls (RPCs), and distributed shared memory (DSM). In synchronous communication, the sender waits for a response from the receiver before continuing, while in asynchronous communication, the sender continues executing without waiting for a response. RPC allows a client process to call a procedure on a server process, which executes the procedure and returns a result. MOM is a messaging paradigm that allows loosely coupled applications to exchange data by sending messages through a middleware layer. In the Actor model, objects called actors communicate with each other by exchanging messages, and each actor can execute concurrently and independently.
- Transparency: A distributed system should be transparent to users and applications, meaning that the system’s underlying structure and location of resources should be hidden. Transparency can be achieved through techniques such as:
- Location Transparency: Location transparency refers to the ability to access resources without knowledge of their physical location. This means that users can access resources in a distributed system without needing to know where they are located or how they are accessed. This can be achieved through the use of naming and addressing techniques that allow resources to be accessed by their logical name or address rather than their physical location.
- Replication Transparency: Replication transparency refers to the ability to access replicated resources without knowledge of their replication. This means that users can access replicated resources without needing to know that they are replicated or where the replicas are located. This can be achieved through the use of replication techniques that ensure that replicas are consistent and up-to-date.
- Concurrency Transparency: Concurrency transparency refers to the ability to access shared resources without knowledge of concurrent access. This means that users can access shared resources without needing to know that other users are accessing them at the same time. This can be achieved through the use of concurrency control techniques that ensure that shared resources are accessed in a mutually exclusive manner.
- Failure Transparency: Failure transparency refers to the ability to access resources without knowledge of failures. This means that users can access resources even if some components of the distributed system have failed. This can be achieved through the use of fault-tolerance techniques that ensure that failures are detected and handled in a transparent manner.
- Fault tolerance: Distributed systems must be designed to tolerate failures, including node failures, network failures, and software failures. Techniques such as replication, redundancy, and failover mechanisms can help to ensure that the system remains operational even in the face of failures.
- Redundancy: This involves duplicating critical components of a system to ensure that if one component fails, the backup component can take over seamlessly. For example, redundant power supplies or redundant servers can be used to ensure that if one fails, the other can continue to function.
- Error detection and correction: This involves using algorithms and protocols to detect errors and correct them automatically. For example, error-correcting codes can be used in data storage systems to ensure that data is stored accurately and can be retrieved even if some errors occur.
- Failover: This involves switching to a backup system in the event of a failure. For example, if a primary server fails, a secondary server can take over automatically and continue to provide services to users.
- Load balancing: This involves distributing the workload across multiple systems to ensure that no single system is overloaded, which can lead to failure. Load balancing can help ensure that systems remain operational even if one or more systems experience failures or errors.
- N-version programming: This involves developing multiple versions of software or hardware to perform the same task, with the goal of ensuring that if one version fails, another can take over. This technique is often used in safety-critical systems, such as those used in aviation or nuclear power plants.
- Scalability: Distributed systems must be designed to scale up or down as the workload changes. Techniques such as load balancing, sharding, and partitioning can help to distribute the workload across nodes and enable the system to handle large volumes of data and users.
- Load balancing: Load balancing involves distributing the workload across multiple servers to avoid overloading any single server. This can be achieved by using hardware or software load balancers that can distribute incoming traffic to different servers based on predefined rules such as round-robin or least-connections.
- Sharding: Sharding involves dividing a large database or data set into smaller, more manageable chunks or shards. Each shard is stored on a different server, and queries are distributed across all the shards. This can help to improve performance and scalability by reducing the load on any one server.
- Replication: Replication involves creating copies of data across multiple servers or resources. This can help to improve availability and performance by allowing multiple servers to handle read requests.
- Clustering: Clustering involves grouping multiple servers together to act as a single system. This can help to improve availability and scalability by allowing the workload to be distributed across multiple servers, and if one server fails, another server in the cluster can take over.
- Content Delivery Network (CDN): A CDN is a network of servers located in different regions around the world. The servers store copies of frequently accessed content, such as images or videos, and can serve the content from the server closest to the user. This can help to improve performance by reducing the distance that data needs to travel.
- Job scheduling: Job scheduling involves distributing workloads to different servers based on their capacity and availability. This can be achieved by using job scheduling software that can distribute tasks based on predefined rules such as priority or load balancing.
- Virtualization: Virtualization involves creating multiple virtual machines or containers on a single server. This can help to improve utilization and flexibility by allowing multiple workloads to run on a single physical server while isolating them from each other.
- Security: Security is a critical concern in distributed systems because of the potential for attacks and unauthorized access. Techniques such as encryption, authentication, and access control can help to protect data and ensure that only authorized users can access the system.
- Encryption: Encryption involves encoding data in such a way that it can only be accessed by authorized users who have the decryption key. This can help to protect data both in transit and at rest.
- Access control: Access control involves restricting access to data to only authorized users. This can be achieved using techniques such as authentication, authorization, and accounting (AAA) or role-based access control (RBAC).
- Data backup and recovery: Data backup and recovery involves creating copies of data and storing them in a secure location. This can help to ensure that data is recoverable in the event of a data loss or corruption.
- Data masking: Data masking involves obscuring sensitive data such as personally identifiable information (PII) to protect it from unauthorized access. This can be achieved by replacing sensitive data with random or fictitious data.
- Intrusion detection and prevention: Intrusion detection and prevention involves monitoring network traffic for signs of unauthorized access or malicious activity. This can be achieved using techniques such as firewalls, intrusion detection systems (IDS), and intrusion prevention systems (IPS).
- Secure coding practices: Secure coding practices involve designing and coding applications with security in mind. This can help to prevent vulnerabilities such as cross-site scripting (XSS) or SQL injection attacks.
- Physical security: Physical security involves protecting the physical infrastructure that stores and processes data. This can be achieved using techniques such as access controls, surveillance cameras, and alarm systems.
- Compliance with data protection regulations: Compliance with data protection regulations such as GDPR or CCPA is critical to protect data. Organizations must implement policies and procedures to ensure that data is collected, processed, and stored in compliance with these regulations.
- Consistency: Maintaining consistency across nodes in a distributed system is challenging because of the possibility of conflicts and failures. Consistency models define how updates to shared data are propagated across the system, and there are various levels of consistency, including strong consistency, eventual consistency, and weak consistency.
- Strong consistency: With strong consistency, all nodes in the distributed system have the most up-to-date version of the data at all times. This ensures that every read operation returns the most recent value and every write operation updates all nodes simultaneously. However, this comes at the cost of availability since write operations may need to wait for all nodes to acknowledge the update before returning a response.
- Eventual consistency: With eventual consistency, nodes eventually become consistent over time, but there may be a delay between updates. This allows read and write operations to proceed without waiting for all nodes to be updated. However, there is a risk of stale reads where a read operation may return an outdated value.
- Read-your-writes consistency: With read-your-writes consistency, a node that has performed a write operation will always see its own updates. This ensures that read operations always return the most recent value for data that the node has written. However, other nodes may not yet have received the update, leading to inconsistent reads from those nodes.
- Session consistency: With session consistency, a node will see its own updates immediately, and other nodes will eventually see the updates within the same session. This ensures that a user’s session is consistent but may not be consistent across all nodes in the system.
- Monotonic consistency: With monotonic consistency, a node will always see the most recent version of the data it has previously read or written. This ensures that read operations are consistent over time but may not be consistent with other nodes.
- Weak consistency is a consistency level in distributed systems where the nodes may not have the most up-to-date version of the data at all times. In other words, weak consistency allows for eventual consistency but with a weaker guarantee. In a weak consistency model, updates to a data item are propagated to some, but not necessarily all, of the nodes in the system. When a node requests a read operation on a data item, it may receive a value that is not the most recent one, or it may even receive conflicting values from different nodes. The amount of time it takes for a node to receive the most recent update depends on the communication delay and the propagation speed of the updates through the network. Weak consistency is often used in systems where high availability and low latency are critical, such as content delivery networks (CDNs) and real-time communication systems. In these systems, it is more important to have low response times and high availability than to have the most up-to-date data at all times. It is important to note that weak consistency does not mean that consistency is completely disregarded. Rather, it is a trade-off between consistency and availability. Weak consistency ensures that the data is eventually consistent across all nodes in the system but may result in a temporary inconsistency between the nodes.
- Resource management: In a distributed system, resources such as CPU, memory, and network bandwidth must be managed efficiently to ensure optimal performance. Techniques such as resource allocation, scheduling, and monitoring can help to ensure that resources are used effectively and efficiently.
- Capacity planning: Capacity planning involves forecasting the future resource requirements based on historical usage data and anticipated growth. This can help organizations to allocate resources more efficiently and avoid bottlenecks.
- Virtualization: Virtualization involves creating virtual versions of resources such as servers, storage, and networks. This can help to optimize resource utilization by allowing multiple applications or users to share a single physical resource.
- Resource pooling: Resource pooling involves aggregating resources from multiple sources to create a shared pool that can be allocated dynamically based on demand. This can help to optimize resource utilization and improve scalability.
- Load balancing: Load balancing involves distributing workload across multiple resources to ensure optimal resource utilization and avoid bottlenecks. This can be achieved using techniques such as round-robin or weighted round-robin, least connections, or IP hash.
- Performance monitoring and optimization: Performance monitoring and optimization involve continuously monitoring resource utilization and performance metrics such as CPU usage, memory usage, and response times. This can help organizations to identify and address performance issues before they become critical.
- Resource scheduling: Resource scheduling involves allocating resources to tasks or applications based on their priority and resource requirements. This can help to ensure that critical tasks or applications have access to the necessary resources while minimizing waste.
- Automation: Automation involves using tools and software to automate resource management tasks such as provisioning, monitoring, and scaling. This can help organizations to reduce the time and effort required to manage resources while improving efficiency and reducing errors.